
Part 1: The Challenges
AI agents have come out from the confines of sketchy accounts on X/Twitter a year ago to the reputable ranks of OpenAI and Anthropic. It seems that almost every task performed on a screen could eventually be handled by one of these agents, and they’ll surely be applied in a wide range of industries in the near future. Once restricted to tool-based agents, which are agents designed to do things for you, simulation agents, which are developed to simulate human behaviour, have come forward as the latest innovation.
AI advocates quickly recognised the potential of simulation agents to conduct cost-effective and scalable research, and Joon Sung Park et al.’s recent paper, Generative Agent Simulation of 1,000 People, demonstrates how meaningful insights can be drawn from synthetic data that mirrors human behaviour. A startup called Synthetic Users is seeking to apply this idea to conduct user research by synthetically generating users—simulation agents—to accelerate and streamline the process. The idea is intriguing, and considering that research is often expensive, slow and messy, there is likely a strong market for it.
Synthetic Users provides a platform where a researcher can define the user group which they want to investigate and then segment it according to their needs. Once the target is specified, a large language model (LLM) then generates five different users with distinct personalities which are then automatically interviewed by the model itself. Once the interviews are generated, a summary report with key findings and insights is generated. The whole process takes about five minutes to complete.
Although this approach offers benefits, it’s not suitable for all kinds of user research, and its benefits and potential drawbacks should be evaluated in light of two critical factors, which I explore in here. The first concerns the lived experience of users, while the second one addresses the deeper implications of what we’re actually doing when we draw insights from synthetically generated data. Before explaining each of these, I’ll briefly describe what synthetic data is.
What is synthetic data?
Synthetic data is artificially generated data that mimics real world data. It has been used across various industries for some time with the aim of providing ”approximately the same answers that would have been obtained if the analysis were run on the original data”1. Its applications span a wide range of fields, including anonymisation, medicine, environmental monitoring, and autonomous driving.
However, applications of synthetic data in the social sciences and user research fields present unique challenges, given the inherently complex nature of human behaviour. In Park’s other paper, Generative Agents: Interactive Simulation of Human Behavior, the researchers approached this challenge by generating simulation agents using LLMs. These agents believably formed a community where they lived, worked and made plans together, successfully mimicking human behaviour.
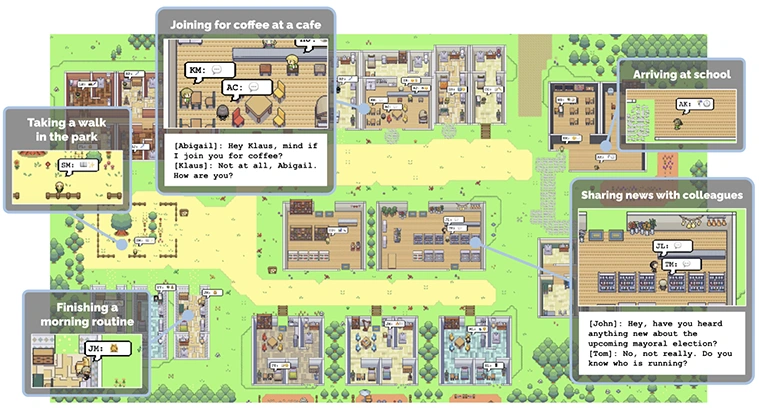
Synthetic data of this kind would be appropriate to simulate behaviour in diverse scenarios, including user research and other social sciences research. With this application, synthetic data can be useful, but also tricky to work with because of what it captures and what it can’t. To get a more specific idea of what is actually being captured, phenomenology offers a useful lens through which to examine these limitations.
What about the lived experiences of users?
Broadly speaking, phenomenology is the study of lived experiences. Developed as a philosophical method in the 20th century, it studies how people experience the world around them. Over time, it developed a series of useful concepts and reflections that illuminate user research and service design. It’s fitting for studying user experience of a product or service, as it provides a foundation for describing human experience holistically.
One foundational concept is worldliness, which situates phenomena—what appears to us, and how it appears—not as isolated elements but as part of a complex, lived, and shared reality. Our own experience of products and interfaces is shaped by the unpredictability and interconnectedness of the world around us. When someone interacts with the design of any app, their life doesn’t pause for that interaction. Everything around them influences their experience.
Conducting research with humans often reveals these nuances. We can learn a great deal about these interactions, —maybe the user is a caretaker who has to juggle various tasks at home, or they are feeling sick on a given day, or have a particular disability. These conditions and worldly situations can be simulated to some extent, but many of the things happening around the use of an app, product or service risk being overlooked.
A recent post on Bluesky aptly illustrates how lack of contextual awareness, or worldliness, can be challenging for current AI systems. Imagine a robot trained to unload a dishwasher. It may perform this task well under “typical” conditions, but would likely struggle if, say, a toddler were actively taking the silverware from the dishwasher and throwing it across the floor. Such unpredictable scenarios are not normally replicated by synthetic environments, yet they significantly shape the user experience and the performance of AI systems.
Similarly, sensory and cognitive experiences (is the app’s notification sound annoying? Are some users feeling excluded due to the language used? Is the placement of a button physically awkward?) could all be very important observations that are not identified because they don’t appear in the model’s output. Moreover, these are all elements that cannot be captured in a text interview alone, because it is often the case that people don’t do or think as they say they do. Non-verbal cues and paralinguistics (the aspects of spoken communication that do not involve words) also play a role in revealing people’s intentions and emotions.
This brings us to a key limitation related to bias and specificity. It has now been extensively documented that LLMs perpetuate, amplify and learn social biases, with these sorts of problems being exacerbated in data-deficient topics, which naturally increase the more specific a situation becomes, or when working with languages that are poorly represented. While some users may fit neatly into broad categories that synthetic models can simulate, user research often seeks to uncover nuances, specificities and edge cases that go beyond surface-level insights.
This limitation raises a more fundamental concern about the accuracy of synthetically generated data and the trustworthiness of the research outcomes derived from it.
Are we learning anything about the world?
Arguably, the purpose of research in general is to learn something about the world. One of the things that caught my attention is that one of Synthetic Users founder’s mentions that the whole idea of synthetic users is possible because LLMs hallucinate. In simple terms, hallucinations are plausible but factually incorrect responses generated by the model. Even though they affect a model’s reliability, they can potentially generate novel ideas or perspectives. However, this seems incompatible with the fundamental purpose of research: learning something about the world in an accurate and trustworthy way. In this view, synthetic users are generating something more akin to a piece of fiction rather than accurate and trustworthy data.
If we understand research in this way, the question becomes: what are we actually studying with synthetic users? If the assumptions underpinning product or service design are based on these simulacra, can the resulting insights be considered meaningful or useful?
This brings me back to the two elements I mentioned, accuracy and trustworthiness. There are occasions when data doesn’t need to be 100% accurate, and “good enough” data suffices. For example, cooking instructions often tolerate a degree of inaccuracy in ingredient measurements without compromising the final dish. However, when the purpose is to obtain highly detailed and contextually-rich data, synthetically generating it becomes less useful, and the risk of drawing incorrect conclusions and insights increases.
Accuracy feeds into the larger issue of trustworthiness—the confidence researchers and stakeholders place in the data. Distrust can erode the credibility of research outcomes and jeopardize the entire design process. Within a team or organization, doubts about the validity of data can lead to resistance to adopting AI-driven methods, even in scenarios where they might be appropriate. In the broader context of user research, the misuse or overreliance on synthetic users could dilute the perceived value of research itself.
To mitigate these risks, it is essential to carefully evaluate when and where synthetic users are appropriate, for example when conducting exploratory and broad-stroked research. However, as I suggested in the introduction, this is just the beginning, and these approaches will inevitably become more robust.
Before committing to using LLMs in this way, it’s worth thinking about the level of inaccuracy and fuzziness that the research you’re conducting can tolerate. It’s not about discarding these products and approaches altogether, but to recognise that they’re not a magical solution to the messiness of research and the complexity of the world.
The second part of this piece will go deeper into the opportunities that these tools open for research.
1 Drechsler, Joerg and Anna-Carolina Haensch, 2023. 30 Years of Synthetic Data.